C++ 一些基础知识
C++ 基础
0. 前置知识
0.1 左/右值
左值:在内存中有明确存储位置(即地址)的表达式,通常出现在赋值表达式的左侧。 左值可以取地址
右值:通常指临时的数据值(如字面量,求值过程中产生的临时对象),在内存中没有固定的地址,它不能被赋值
0.2 单位
bit:比特,又称位,计算机内部储存数据的最小单位
Byte:字节,由8个比特组成,习惯上以大写B来表示,通常1个字节可以存入一个ASCII码,2个字节可以存放一个汉字国标码。这是内存寻址的最小单元
word:字,由一个或多个字节组成,计算机的字长决定了其CPU一次操作实际处理的位数是多少,例如64位计算机的CPU一次最多能处理64位数据
0.3 内存
内存就是计算机的存储空间,用来存储程序的指令,数据和状态
0.3.1 内存四区
-
代码区(code/text):存放CPU执行的机器指令。通常代码区是可共享的,即另外的程序可以调用它。编写的所有代码都会放进代码区,其特点是共享和只读
-
全局区/静态区(stactic):用来存放全局变量,静态变量,常量
- data区:存放已初始化的全局变量,静态变量和常量
- bss区:存放初始化为0或者NULL或未初始化的全局变量,静态变量和常量。未初始化的在程序执行前会自动被系统初始化为0或者NULL
- 常量区:顾名思义,存放常量,如const修饰的全局变量,字符串常量
-
栈(stack):是一种先进后出的内存结构,由编译器自动分配
-
结构体和类的对象在默认情况下是分配在栈区
-
存放函数的参数值,返回值,局部变量等,由const定义的局部变量也存储在栈里。
-
内存地址由高到低方向生长,其最大大小由编译时确定,速度快但自由性差,最大空间比堆小
-
-
堆(heap):用于动态内存分配
- 内存地址由低到高方向生长,其大小由系统内存/虚拟内存上限决定,速度较慢,但自由性大,可用空间大
- 注意进行内存释放,否则会造成内存泄露

0.3.2 内存编址
即给计算机的存储单元进行编号,而在CS中存储单元通常是指最小的可寻址单元即byte,也就是给每个byte一个编号,这个编号就是内存的地址
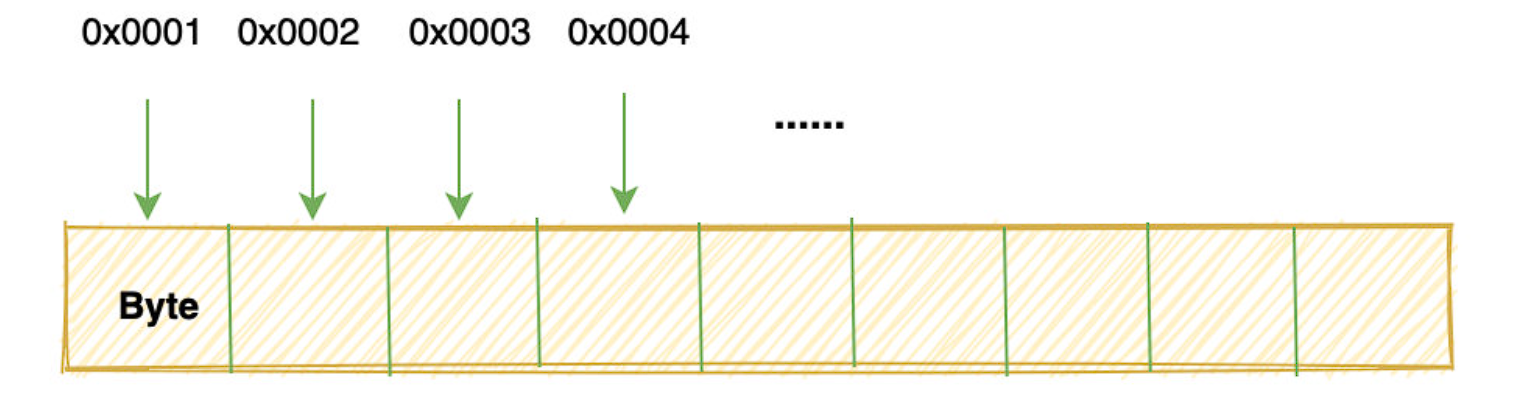
0.3.3 内存地址空间
将所有byte的编号连起来就叫作内存的地址空间,而地址空间(可寻址内存)的大小与电脑是32位还是34位有关
-
32 位意味着可寻址的内存范围是
2^32 byte = 4GB -
64位即
2^64 byte
0.4 原码 反码 补码
-
反码 原码按位取反 正数的反码是其本身
-
补码 原码按位取反加一 正数的补码是其本身
-
计算机中使用补码来表示和操作整数
-
个人觉得反码和补码的引入 是为了便于理解在计算机中如何使用 正数来表示负数
如 int 在内存中占据4个字节 表示有符号的整数 他的范围是 [-2^31 , 2^31 - 1]
unsigned int 在内存中占据四个字节 表示无符号整数 他的范围是[0,2^32-1]
而32位二进制数表示的范围是[0,2^32-1],即把它从中间分一半,将 0 开头的32位二进制数用来表示正数,将 1 开头的用来表示负数,所以int表示的正数的范围是unsigned int 的一半 但二者表示的总数是一样的
0.5 进制转换
十进制: 都是以0-9这九个数字组成,不能以0开头。
二进制: 由0和1两个数字组成。
八进制: 由0-7数字组成,为了区分与其他进制的数字区别,开头都是以0开始。
十六进制:由0-9和A-F组成。为了区分于其他数字的区别,开头都是以0x开始。
-
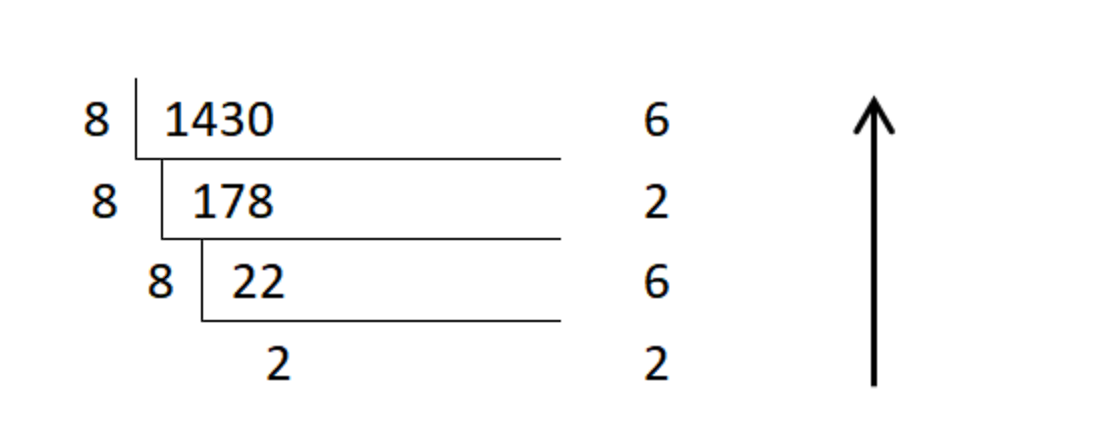
整数部分
十进制转n进制:十进制数除以2,反向取余数,直到商为0终止
![image-20240408204846887]()
n进制转十进制:将每一位乘以相应的权值,然后将乘积相加
-
小数部分
十进制转n进制: 乘n取整,顺序输出
n进制转十进制:如上
1.变量
变量名是变量地址的符号化体现
1.1 变量类型
1.1.1 作用:
-
内存分配:告诉编译器该变量占据的内存大小,占了多少个字节
-
操作限制:规定了该变量可以执行的操作
-
数据解释:决定了如何解释存储在内存中的位模式,决定了编译器如何解读对应的二进制数据
位模式是指一系列的0和1,是计算机内存中数据最基本的形式,所有数据最终都会被表示为 位模式
1.1.2 种类
-
基础类型 :整数 字符 布尔 浮点
-
修饰符:long short signed unsigned
-
类类型:class
-
结构体类型:struct
-
数组类型
-
指针类型
-
引用类型
-
复数类型(complex C++11及以上)
-
联合体 unio
-
枚举体 enum
2. 内存对齐
为了提高数据访问的性能和效率,将数据存储在适当的内存地址上,以减少额外开销 以空间换时间
对齐的长度一般为2的n次幂(1,2 ,4,8)
2.1 产生原因
为了适应CPU读取数据的行为,CPU一次读取4个字节或8个字节,由编译器和操作系统(32位或64位)决定
2.2 更改对齐规则
-
使用编译器指令
(如 #pragma pack)更改默认的对齐规则。这个命令是全局生效的。这可以用于减小数据结构的大小,但可能会降低访问性能。 -
在 C++11 及更高版本中,可以使用 alignas 关键字为数据结构或变量指定对齐要求。这个命令是对某个类型或者对象生效的。例如,
alignas(16) int x; 将确保 x 的地址是 16 的倍数。
1 |
|
2.3 结构体对齐
-
最大成员对齐:编译器会将数据成员补齐为最大成员大小的整数倍
如果结构体中含有数组成员,如 char a[5],它的对齐方式和连续写 5 个 char 类型变量是一样的,也就是说它还是按一个字节对齐
-
填充字节(struct padding):如果某成员大小满足对齐要求,编译器会插入一些字节进行填充
1 |
|

1 |
|

2.4 类的内存对齐
2.4.1 空类的大小
空类和空结构体的实例化对象的大小都为1
1 |
|
2.4.2 添加成员函数,静态数据成员,静态成员函数
结果依旧为1
1 |
|
因为成员函数,静态成员函数存储在代码段(.text)中,静态成员变量存储在全局/静态区(static),他们不占用类的内存,不是每个对象分别存储
2.4.3 类对象大小的影响因素
非静态成员变量和虚函数
考虑是否存在vptr,若存在则计入考虑范围,整体上与结构体相同
3.类的多态
允许使用一个接口来表示不同的类,而这些类的对象在运行时可以表现出不同的行为
父类指针可以指向子类对象,进而调用子类函数
3.1 虚表(vtable)
-
每个存在虚函数的类,都有一个虚函数表
-
虚函数表是一个指针数组,其元素是指向虚函数的函数指针(函数的地址)
-
成员函数(包括虚函数)是类的一部分,不占用对象实例的内存空间,他们为同一个类的所有对象共享,存储在程序的代码段中
3.2虚表指针(vptr)
实现多态类的核心机制之一
每一个包含虚函数的类 的实例化对象所包含的隐含指针
-
该指针指向类的虚表
-
大多数实现上,虚函数表指针一般都放在对象第一个位置
-
该指针是隐含的,不是类的成员变量,用户不能直接访问或修改它
-
指针大小取决于操作系统或编译器,32位占4个字节,64位占8个字节
3.3 多态的实现
-
当派生类重写了基类的虚函数时,派生类的虚表中对应的函数指针将被更新,指向派生类中的新实现,即指向派生类中重写函数的地址

4. 移动语义
允许资源从一个对象转移到另一个对象 避免了复制 提高了性能
在使用一个右值(即将被销毁的的对象)去初始化同类对象时该函数会被调用
如果一个类定义了移动构造函数或移动赋值运算符也必须定义拷贝操作,否则无法进行拷贝操作,哪些成员默认被删除

4.1 特点
-
函数名和类名相同 无返回值 因为它本身也是一个构造函数
-
第一个参数为同类型的右值引用(&&)
-
第一个参数不能设置为const因为它的资源在函数内部会被移动给当前对象
-
移动构造函数执行后 需要确保右值引用的对象能被正确销毁
4.2 实例
1 | class CDate{ |
由于移动操作“ 窃取” 资源, 它通常不分配任何资源。 因此, 移动操作通常不会抛出任何异常。不抛出异常的函数应该使用 noexcept 通知标准库,避免编译器为了处理异常而作一些额外的工作
4.3 融合拷贝赋值运算符与移动赋值运算符
1 | CDate& CDate::operator=(CDate date){ |
5. 完美转发 std::forward
在通用引用的情境下,尽可能使用
forward()
5.2 通用引用(universal reference)
构成通用引用的条件
-
必须满足
T&&这种形式 -
类型
T必须是通过推断得到的
产生通用引用的可能情况
-
函数模板参数(function template parameters)
1
2template <typename T>
void f(T&& param); -
auto声明(auto declaration)1
auto && var = ...;
-
typedef声明(typedef declaration) -
decltype声明(decltype declaration)
与其他引用的区别
会产生引用合成
1 | T& & => T& |
该合成规则用户是不允许使用的,只有编译器才能够使用这种合成规则
6.删除的函数(deleted function)
指使用delete的函数 表示这类函数被禁用 不能被调用
当尝试调用一个被删除的函数时,编译器将会报错,指出该函数是被删除的,从而在编译时期提供了一种检查机制,防止了不期望的函数调用
用途
-
防止拷贝:如果你有一个类,你不希望它的实例被拷贝,你可以删除拷贝构造函数和拷贝赋值运算符。
-
防止移动
-
限制某些函数的使用:可以删除那些不应该被调用的函数版本,比如禁止某些类型的参数
1 | class OnlyInt { |
7. 多线程编程
7.1 同步问题(Synchronization Issues)
同步问题发生在当多个线程需要访问共享资源或数据,并且这些访问需要以某种特定的顺序执行时。如果同步不当,可能会导致数据不一致或竞态条件(Race Conditions)。
例子:
-
竞态条件:
- 两个线程同时读取一个共享变量,然后基于这个变量的值进行计算,最后将结果写回。如果两个线程同时读取到相同的值,然后都进行计算并写入,那么一个线程的写入可能会覆盖另一个线程的结果,导致错误。
-
死锁:
- 线程A持有资源1并等待资源2,而线程B持有资源2并等待资源1。如果线程A和B都不释放它们持有的资源,那么它们将永远等待对方释放资源,导致程序无法继续执行。
-
饥饿:
- 一个线程因为优先级较低,始终无法获得它需要的资源,即使这些资源在其他线程中是可用的。
为了解决同步问题,通常会使用以下机制:
-
互斥锁(Mutexes):确保同一时间只有一个线程可以访问共享资源。
-
条件变量(Condition Variables):允许线程在某些条件下挂起或被唤醒。
-
读写锁(Read-Write Locks):允许多个读操作同时进行,但写操作需要独占访问。
-
原子操作(Atomic Operations):提供不可分割的操作,确保在多线程环境中对数据的操作是安全的。
7.2 并发问题(Concurrency Issues)
并发问题是指多个线程同时执行,可能会导致性能问题或者需要特别设计算法来确保正确性的问题。
例子:
-
线程安全:
- 一个线程正在修改一个数据结构,而另一个线程正在读取该数据结构。如果修改操作不是原子的,那么读取操作可能会得到不一致的数据。
-
内存可见性:
- 一个线程修改了一个共享变量,但这个修改对其他线程来说不是立即可见的。这可能导致其他线程读取到旧值。
-
性能问题:
- 过多的线程竞争同一个资源可能会导致性能下降,因为线程需要频繁地等待资源变得可用。
为了解决并发问题,通常会使用以下策略:
-
线程池:限制同时运行的线程数量,避免创建过多的线程导致的性能问题。
-
无锁编程(Lock-Free Programming):使用原子操作来避免锁的使用,提高并发性能。
-
并行算法设计:设计可以同时在多个处理器上运行的算法,以利用多核处理器的优势
7.3 Mutex的种类
1. std::mutex (基本互斥锁)
std::mutex是C++标准库中提供的最基本的互斥锁类型之一。它用于实现线程间的互斥访问,即在一个时间点只允许一个线程获得锁,其他线程需要等待锁被释放才能继续执行。使用std::mutex可以保证多个线程对共享资源的访问顺序,并避免数据竞争产生的问题。
常用函数
-
lock() 尝试获取互斥锁。如果未被其他线程占用,则当前线程获取锁;否则阻塞等待锁的释放。
-
unlock() 释放互斥锁。如果当前线程持有锁,则释放锁;否则行为未定义。
-
try_lock() 尝试获取互斥锁,不会阻塞线程。如果未被其他线程占用,则当前线程获取锁并返回true;否则返回false。
2. std::recursive_mutex (递归互斥锁)
std::recursive_mutex是C++标准库中提供的一个递归互斥锁类型,用于实现线程间的互斥访问。与std::mutex相比,std::recursive_mutex可以允许同一线程多次获取互斥锁,而不会导致死锁。简单来说就是允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,释放互斥量时需要调用与该锁层次深度相同次数的 unlock()
std::recursive_mutex定义在
1 |
|
当同一线程多次尝试获取std::recursive_mutex时,它不会导致死锁,而是允许同一线程多次获取锁,需要相应次数的解锁操作才能完全释放锁。